
GraphQL in Spring Boot(三) DataLoader 解決 Resolver 重複執行問題
2022, Jan 07
還記得在第一篇的時候介紹到的 Field Resolver,當 Client 有用到某個 Field 的時候才會去執行取得資料,但是當回傳是一個 List 的時候會發生每個 Element 都要執行一次查詢,有時候甚至是拿同一筆資料,這樣對效能是一個不必要的消耗,DataLoader 也因應而生
沒看過前幾篇的可以點這邊:
測試情境
用之前那篇的情境來說明
- Schema
type Post{
id: ID!
content:String
author:User!
creationTime: String!
}
type Query{
postList:[Post!]!
}
- Java 實作
@Component
@Slf4j
public class PostQuery implements GraphQLQueryResolver {
@Autowired
private PostDao postDao;
public List<Post> getPostList() {
return postDao.findAll();
}
}
@Slf4j
@Component
public class PostResolver implements GraphQLResolver<Post> {
@Autowired
private UserDao userDao;
public User getAuthor(Post post) {
return userDao.findById(post.getAuthorId()).get();
}
}
在取得 PostList 的時候會像下面那樣得到所有 Post 的作者
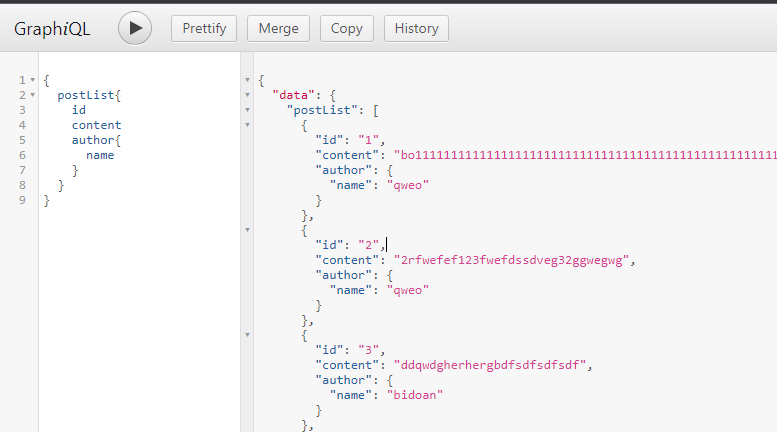
可以開啟 Hibernate 的 Log 看到送出去的語法,明顯可以了解到條目非常多

可以知道他是每一個元素都去執行一次 getAuthor(Post post),這樣對效能是一個不必要的消耗,以這個測試環境來說作者只有兩個,不需要跟 DB 取資料這麼多次,再者以 DB SQL 的操作來說是可以一次就取得我們要的所有資料的
DataLoader
為了解決上述的問題我們要用到一個 DataLoader 的機制,簡單的說就是把要拿的資料參數先收集起來,收集完畢之後再一次進行 Query,把操作集中處理
- 首先先寫一個
DataLoader的執行方法,看到DataLoaderFactory.newDataLoader裡面,由於輸入參數是userId最後會被收集成一個List,然後再用Dao一次拿到所有的 ID 資料,這邊的KEY等會會用到
@Component
public class AuthorDataLoader {
public static final String KEY = "AUTHOR_DATA_LOADER";
private final Executor executor = Executors
.newFixedThreadPool(Runtime.getRuntime().availableProcessors());
@Autowired
private UserDao userDao;
public DataLoader<Long, User> getLoader() {
return DataLoaderFactory.newDataLoader((List<Long> userIds) ->
CompletableFuture.supplyAsync(() -> userDao.findAllById(userIds), executor));
}
}
- 上面定義完
DataLoader之後呢還要註冊到GraphQLContext之中,這樣 GraphQL 的請求才會通過這個DataLoader,KEY用來識別不同的DataLoader
@Component
public class CustomGraphQLContextBuilder implements GraphQLServletContextBuilder {
@Autowired
private AuthorDataLoader authorDataLoader;
@Override
public GraphQLContext build() {
return new DefaultGraphQLContext();
}
@Override
public GraphQLContext build(HttpServletRequest httpServletRequest, HttpServletResponse httpServletResponse) {
return DefaultGraphQLServletContext.createServletContext()
.with(httpServletRequest)
.with(httpServletResponse)
.with(buildDataLoaderRegistry())
.build();
}
@Override
public GraphQLContext build(Session session, HandshakeRequest handshakeRequest) {
return DefaultGraphQLWebSocketContext.createWebSocketContext()
.with(session)
.with(handshakeRequest)
.with(buildDataLoaderRegistry())
.build();
}
public DataLoaderRegistry buildDataLoaderRegistry() {
DataLoaderRegistry registry = new DataLoaderRegistry();
registry.register(AuthorDataLoader.KEY, authorDataLoader.getLoader());
return registry;
}
}
- 最後別忘了在
Resolver的地方要換成使用DataLoader的方式執行
@Component
public class PostResolver implements GraphQLResolver<Post> {
public CompletableFuture<User> getAuthor(Post post, DataFetchingEnvironment environment) {
DataLoader<Long, User> dataLoader = environment.getDataLoader(AuthorDataLoader.KEY);
return dataLoader.load(post.getAuthorId());
}
}
再來看一次 Hibernate 的 Log,只剩下兩行了,一次拿到所有的 Post,一次拿到其下的作者,這說明 DataLoader 有正常作用著,也達到了節省效能的目的

結語
DataLoader 很好的解決了 Resolver 重複執行的問題,但其實筆者還是不太明白是怎麼對應到正確的值的,撰寫的程式碼中並沒有比對的部分,這點讓我有點疑惑,如果機制不單純的話很可能會有想不到的副作用產生